
동기/비동기 처리를 이해하기 위해 먼저 짚고 넘어가야 할 개념인 것 같아 I/O에 대해 정리해본다.
I/O 개념 정리
동기/비동기 처리를 이해하기 위해 먼저 짚고 넘어가야 할 개념이 바로 I/O다. 이를 정리해보자.
I/O란 쉽게 말해 데이터의 입출력(Input/Output)을 의미한다. 우리가 알고 있듯이 운영체제(OS) 환경에서는 CPU가 데이터 연산을 담당하고, RAM은 데이터를 임시로 저장하며, 디스크는 영구 저장소 역할을 하는 등 각 구성 요소가 역할을 나누어 작업을 처리한다.
따라서 특정 작업을 수행하기 위해 데이터가 한 요소에서 다른 요소로 이동하게 되는데, 이때 발생하는 데이터 이동 과정을 I/O라고 한다.
Block I/O
Blocking I/O에서는 I/O 작업을 요청한 프로세스나 스레드가 해당 요청이 완료될 때까지 block 상태로 전환되어 대기한다.
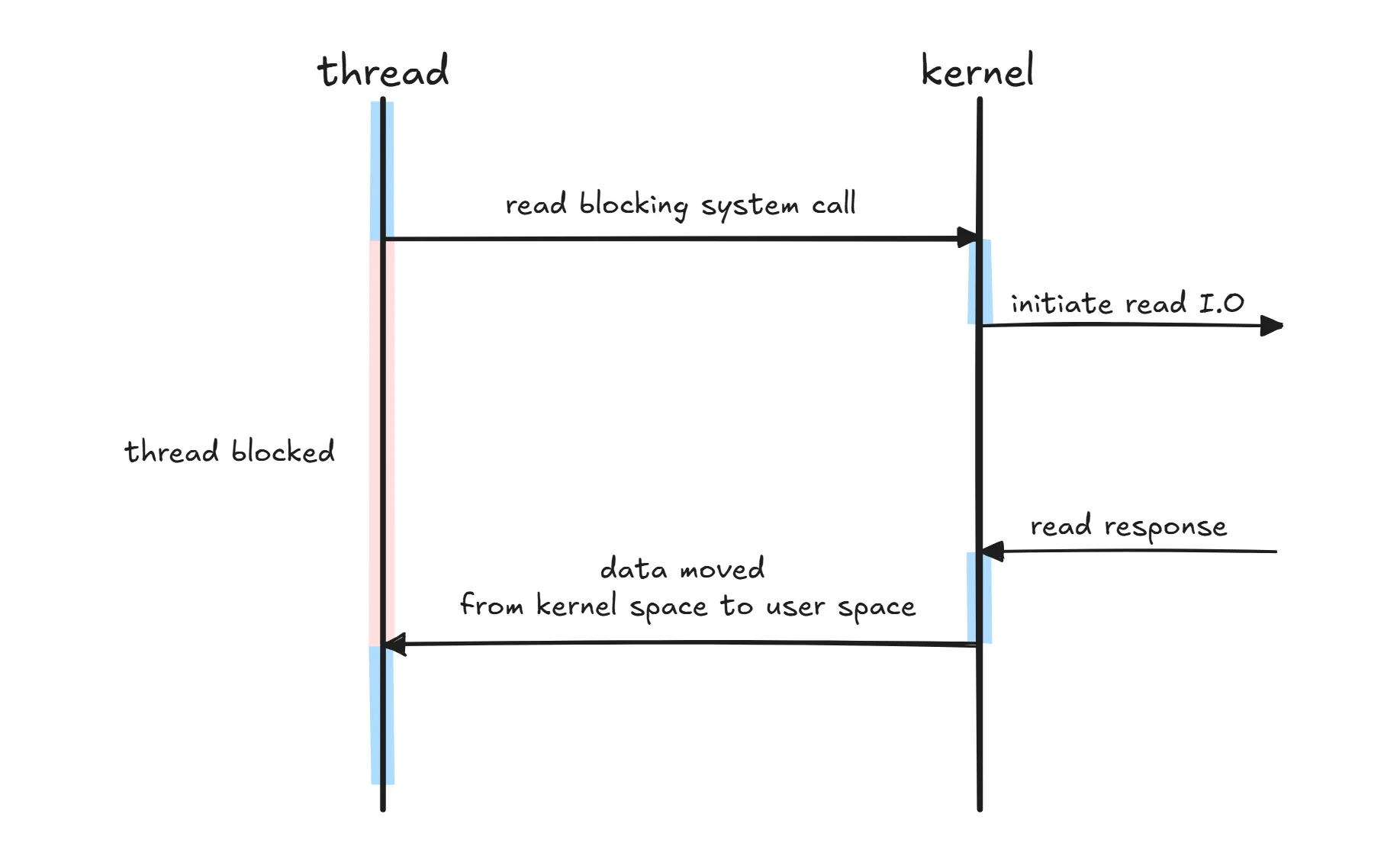
동작 과정을 살펴보면 다음과 같다. 스레드가 read blocking system call을 호출하면, 즉시 block 상태로 전환되어 실행을 멈춘다. 이후 커널(Kernel)이 I/O 작업을 시작(initiate read I/O)하고, 데이터 준비가 완료되면 응답(read response)을 반환한다. 이 과정에서 데이터는 커널 공간(Kernel Space)에서 사용자 공간(User Space)으로 복사(data moved)되며, 이 복사가 완료된 이후에야 스레드는 다시 실행 상태로 돌아가 다음 작업을 수행할 수 있다.
Socket에서의 Block I/O
소켓 환경에서의 Blocking I/O를 이해하기 위해서는 TCP 통신에서 사용되는 송신 버퍼(send buffer)와 수신 버퍼(recv buffer)의 존재를 먼저 이해해야 한다. 또한 백엔드 애플리케이션에서 발생하는 I/O의 대부분은 네트워크 통신과 관련되어 있기 때문에, 이러한 관점에서 소켓 기반 I/O를 중심으로 설명할 수 있다.
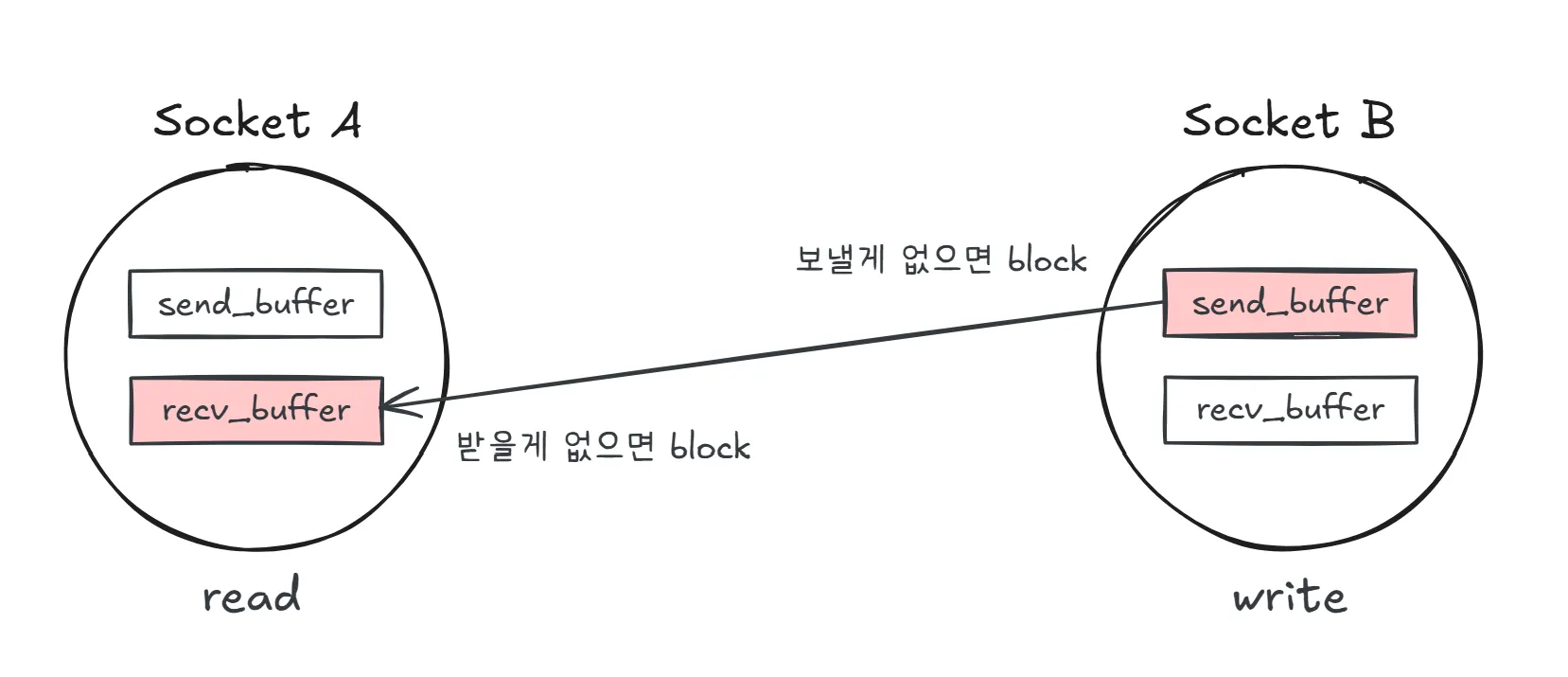
- 수신(Read) 측의 블록: Socket A가 read를 호출했을 때, 만약 수신 버퍼(recv_buffer)에 읽을 데이터가 없다면 데이터가 들어올 때까지 블록 상태에 빠진다.
- 송신(Write) 측의 블록: 반대로 Socket S가 write를 하려고 할 때, 송신 버퍼(send_buffer)가 가득 차 있어 데이터를 더 넣을 수 없다면 공간이 확보될 때까지 블록 상태가 된다.
이처럼 소켓 I/O에서는 버퍼의 상태에 따라 프로세스나 스레드가 block 상태에 빠질 수 있다.
Non-blocking I/O
Non-blocking I/O는 프로세스나 스레드를 block 상태로 만들지 않고, 요청에 대한 현재 상태를 즉시 반환한다. 호출 결과를 바로 돌려받기 때문에 스레드는 대기하지 않고 다른 작업을 계속 수행할 수 있다.

스레드가 read non-blocking system call을 호출했을 때 데이터가 준비되지 않은 상태라면, 커널은 -1(EAGAIN 또는 EWOULDBLOCK)을 즉시 반환한다. 이때 스레드는 block되지 않고 실행 상태를 유지한 채 다른 로직을 수행한다. 이후 다시 시스템 콜을 호출했을 때 데이터가 준비되어 있다면, 커널 공간에서 사용자 공간으로 데이터가 복사되며 I/O 작업이 완료된다.
Socket에서의 Non-Block I/O
소켓 환경에서의 Non-blocking I/O는 버퍼 상태를 확인한 뒤, 즉시 처리할 수 없는 경우에도 대기하지 않고 결과를 반환하는 방식이다.

- 수신(Read) 측의 동작: recv_buffer에 데이터가 있는지 확인한다. 원래 Blocking 방식이라면 데이터가 들어올 때까지 블록 상태에 처하지만, Non-blocking 방식에서는 데이터가 없다면 "현재 읽을 데이터가 없음"을 즉시 알리고 종료한다.
- 송신(Write) 측의 동작: send_buffer 역시 마찬가지다. 데이터를 쓰려고 할 때 버퍼에 공간이 없다면, 공간이 생길 때까지 블록 상태로 기다리는 것이 아니라 즉시 작업을 종료하고 다음 로직으로 넘어간다.
이처럼 소켓에서의 Non-blocking I/O는 버퍼의 상태에 관계없이 프로세스나 스레드가 제어권을 즉시 돌려받아 다른 일을 할 수 있게 한다.
I/O 작업의 종료를 어떻게 알 수 있을까?
위의 그림을 보면 알 수 있듯이, 스레드는 I/O 작업을 요청한 뒤 해당 작업이 완료될 때까지 아무 일도 하지 않고 기다리는 것이 아니라 다른 작업을 수행한다. 그리고 요청한 I/O 작업이 실제로 완료되었을 때 다시 해당 작업을 이어서 처리한다.
그렇다면 여기서 한 가지 의문이 생긴다.
스레드는 커널에서 수행되던 I/O 작업이 언제 끝났는지를 어떻게 알 수 있을까?
폴링(Polling)
Non-blocking 방식에서 I/O 작업이 끝났는지 확인하기 위해 가장 먼저 떠올릴 수 있는 방법은 반복적으로 상태를 확인하는 폴링(Polling)이다. 하지만 이 방식은 몇 가지 명확한 문제점을 가지고 있다.
- 지연 시간(Latency) 발생: 반복적으로 호출하기 때문에, 실제로는 작업이 이미 완료되었더라도 다음 호출 타이밍이 올 때까지 지연 시간이 생길 수밖에 없다.
- CPU 자원 낭비: 데이터가 준비되지 않았음에도 계속해서 시스템 콜을 날리기 때문에 무의미한 CPU 소모가 발생한다.
- 비용 문제: 관리해야 할 소켓 연결이 많아질수록 각각의 상태를 일일이 확인해야 하므로 전체적인 시스템 비용이 급격히 증가한다.
이러한 지연 문제를 해결하기 위한 방법으로 멀티스레드로 폴링을 분산하면 어떨까? 여러 스레드가 소켓을 나누어 담당하면, 각 소켓의 상태를 더 자주 확인할 수 있고 결과적으로 지연 시간은 줄어들 수 있다.
그러나 이는 근본적인 해결책이 되기 어렵다. 일을 여러 스레드로 나누었다고 해도, 각 폴링 작업은 결국 CPU에서 수행된다. 즉, 멀티스레드 폴링은 구조적으로 폴링 주기를 더 촘촘하게 만든 것과 다르지 않다. 지연 시간은 줄일 수 있지만, 그만큼 불필요한 시스템 콜과 CPU 사용량은 오히려 증가한다.
결과적으로 멀티스레드 폴링은 지연 문제를 완화할 수는 있으나, CPU 자원 낭비와 비용 문제를 해결하지는 못한다. 오히려 폴링 빈도가 높아질수록 쓸데없는 비용 역시 함께 증가하게 된다.
I/O multiplexing
멀티스레드는 I/O 작업을 여러 스레드로 나누어 처리하는 방식이라면, I/O Multiplexing은 여러 I/O 작업을 하나의 스레드로 관리하기 위한 방식이다. 관심 있는 여러 I/O 작업을 동시에 모니터링하고, 그중 처리가 가능한 작업이 발생했을 때 이를 한 번에 알려준다. 이러한 특성 때문에 다수의 연결을 효율적으로 관리해야 하는 네트워크 통신에서 주로 사용된다.
멀티스레드는 일(I/O 작업)을 여러 스레드로 나누는 방식이고
I/O 멀티플렉싱은 여러 I/O 작업을 하나의 스레드가 감시하고 처리하는 방식이다.

위 그림은 Blocking 모드의 I/O Multiplexing을 나타낸다. 하나의 스레드는 여러 소켓을 동시에 감시하며, 읽을 수 있는 데이터가 준비될 때까지 block 상태로 대기한다. 이때의 block은 각 소켓에서 read를 수행하며 기다리는 것이 아니라, 어떤 소켓이 읽기 가능한 상태가 되었는지를 기다리는 것이다.
여러 read 대상이 준비되면 커널은 이를 한 번에 스레드에게 통지하고, 스레드는 block 상태에서 깨어나 준비된 소켓들에 대해 non-blocking read를 순차적으로 수행한다. 이미 데이터는 커널 버퍼에 준비되어 있으므로, 추가적인 block 없이 즉시 처리된다.
사실 I/O 멀티플렉싱에는 다양한 구현 방식이 존재한다. 각 방식은 동작 원리와 특성이 조금씩 다르기 때문에, 다음 글에서는 이러한 I/O 멀티플렉싱의 여러 종류에 대해 자세히 알아보자.
쉬운코드: BJ.19 block I/O vs non-block I/O 설명합니다! 소켓 I/O 예제로 주로 설명해요. I/O multiplexing도 설명합니다
'CS > OS' 카테고리의 다른 글
| 비동기/ 동기가 뭐길래.. (2) | 2026.01.21 |
|---|---|
| I/O Multiplexing: Reactor 와 Proactor (IOCP) (0) | 2026.01.21 |
| I/O Multiplexing: Select, Poll, 그리고 Epoll (0) | 2026.01.19 |