
백엔드 개발을 하다 보면 동기(synchronous), 비동기(asynchronous)라는 말을 정말 자주 듣게 된다. 멀티플렉싱을 공부할 때도 그렇고, Spring을 쓰다 보면 “이건 동기로 할까, 비동기로 할까?” 같은 이야기를 계속 하게 된다. 그런데 막상 누가 설명해보라고 하면 어딘가 애매해진다. 대충은 아는 것 같은데, 정확히 말로 풀기는 어렵다.
그래서 이번에는 이 개념들을 한 번 제대로 정리해보려고 한다. 프로그래밍 관점에서 시작해서 I/O 관점, 그리고 백엔드 아키텍처 관점까지 이어서 보면서 동기와 비동기를 다시 정렬해보는 게 목표다. 이미 들어본 이야기들이 많겠지만, 이번 글에서는 “왜 이렇게 이해하는 게 맞는지”에 조금 더 집중해보려고 한다. 쉬운코드를 보면서 들었던 내용들을, 내 나름대로 정리하고 해석해본다.
프로그래밍 관점에서의 동기와 비동기
동기(Synchronous) 프로그래밍
동기 프로그래밍은 여러 작업을 순차적으로 실행하는 방식이다. 어떤 작업을 호출하면 그 작업이 끝날 때까지 다음 단계로 넘어가지 않는다. 흐름이 직관적이고 이해하기 쉽지만, 하나의 작업이 지연되면 전체 흐름이 함께 느려진다는 단점이 있다.

비동기(Asynchronous) 프로그래밍
비동기 프로그래밍은 여러 작업을 독립적으로 실행하도록 구성한다. 작업을 요청만 해두고 결과는 나중에 callback, event, future 같은 방식으로 처리한다. 흐름이 분리되기 때문에 구조는 복잡해질 수 있지만, 동시에 여러 작업을 처리할 수 있다는 장점이 있다.

비동기 프로그래밍과 멀티스레딩은 다르다
그림으로 보면 비동기 프로그래밍은 멀티스레딩과 비슷해 보인다. 실제로 동시에 여러 작업이 실행되는 것처럼 보이기 때문이다. 하지만 둘은 같은 개념이 아니다. 비동기는 프로그래밍 모델이고, 멀티스레딩은 이를 구현하는 방법 중 하나다. 비동기를 가능하게 하는 방식에는 크게 두 가지가 있다.
첫 번째는 멀티스레딩이다.

위 그림처럼 각 스레드는 자신만의 작업 흐름을 가진다. thread 1은 A를 처리한 뒤 C를 처리하고, thread 2는 B를 처리한 뒤 D를 처리한다. 작업들이 서로 다른 스레드에서 동시에 실행되기 때문에 멀티 코어를 활용할 수 있고, 하나의 작업이 오래 걸려도 다른 스레드는 계속 일을 할 수 있다. 하지만 스레드가 많아질수록 context switching 비용이 증가하고, race condition 같은 동시성 문제가 발생할 수 있다. 또한 스레드 풀 고갈이라는 현실적인 문제도 함께 고려해야 한다.
두 번째는 논블로킹 I/O다.

이 경우에는 멀티스레드처럼 보이지만 실제로는 하나의 스레드에서 작업이 처리된다. A와 B, C와 D는 서로 다른 스레드에서 실행되는 것이 아니라, 하나의 스레드가 I/O 작업을 기다리지 않고 다음 작업으로 넘어가는 구조다. I/O 작업은 OS나 시스템에 맡겨두고, 완료되면 이벤트나 콜백 형태로 다시 처리된다. 그동안 스레드는 다른 작업을 수행할 수 있기 때문에, 싱글 스레드여도 비동기 처리가 가능하다.
이 방식의 핵심은 스레드가 멈추지 않는다는 것이다. CPU 작업과 I/O 작업을 겹쳐서 수행할 수 있기 때문에, 적은 수의 스레드로도 높은 처리량을 낼 수 있다. 그래서 요즘 백엔드 시스템에서는 멀티스레드를 무작정 늘리기보다는, 논블로킹 I/O를 활용해 효율을 높이려는 방향으로 발전하고 있다.
I/O 관점에서 본 동기와 비동기
I/O 관점에서 동기와 비동기를 보면 정의가 조금씩 달라져서 더 헷갈리기 쉽다. 흔히 동기 I/O를 블로킹 I/O, 비동기 I/O를 논블로킹 I/O로 설명하는 경우가 많다. 개념을 처음 이해하는 데는 도움이 되지만 항상 정확한 정의는 아니다.
보다 본질적인 차이는 제어 책임에 있다. synchronous I/O에서는 요청자가 I/O 완료 여부를 직접 책임지고 확인해야 한다. 반면 asynchronous I/O에서는 I/O가 완료되면 시스템이 notify 해주거나 callback을 호출해준다. 이 관점이 동기와 비동기의 차이를 가장 잘 설명한다.
이렇게만 들으면 이해가 안된다. 그래서 각 케이스에 대해 생각을 더 해봤다.
Synchronous + Blocking
가장 고전적인 케이스이고 이해가 쉬운 케이스이다. 동기적으로 처리하면서 I/O 때문에 블로킹이 발생하는 상황이다.

말로 풀면, 동기는 제어 흐름을 호출자가 책임지는 방식이다. 즉 무엇인가를 호출했을 때 그 호출의 결과(성공/실패 포함)를 끝까지 챙기고, 그 결과를 받아 다음 흐름으로 이어가는 구조다. 그런데 이 과정에서 I/O가 끼어 있으면, 결과가 돌아올 때까지 호출한 스레드가 멈추게 된다. 그래서 “동기 + 블로킹”은 결국 호출한 스레드가 I/O를 기다리면서 흐름이 멈춰 있는 상태라고 볼 수 있다. 전통적인 Spring MVC + JDBC 같은 조합이 딱 이 형태이고, 요청 하나당 스레드 하나가 붙어서 처리하다가 DB나 외부 API 응답을 기다리는 동안 그 스레드는 아무 일도 못 한다.
Synchronous + Non-Blocking
동기인데 논블로킹이라는 말이 처음엔 이상하게 들린다. 그런데 동기의 핵심은 “내가 결과를 챙긴다”는 점이고, 논블로킹의 핵심은 “스레드가 멈추지 않는다”는 점이다. 이 조합에서는 호출한 쪽이 결과를 끝까지 책임지긴 하지만, 기다리는 방식이 ‘멈춰서 기다리기’가 아니라 ‘상태를 직접 확인하는 방식’이 된다.
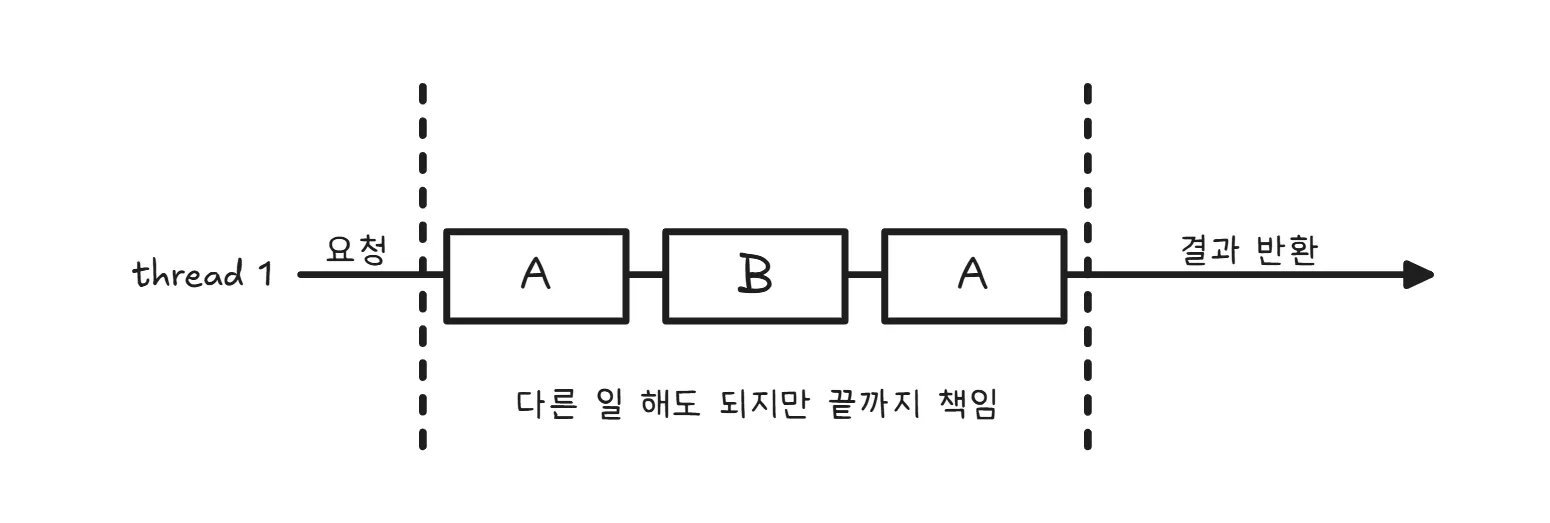
즉 I/O 요청을 던져놓고 스레드는 계속 실행되며, “끝났나?”를 반복해서 확인하거나(폴링), 준비된 순간에만 다시 처리 흐름을 이어간다. 여기서 중요한 건, 결과가 준비되었는지 확인하는 책임이 여전히 호출자에게 있다는 점이다. 그래서 스레드는 멈추지 않지만, “완료 여부를 내가 직접 챙긴다”는 의미에서 여전히 동기다. epoll 같은 readiness 기반 모델이 이런 감각에 가깝다(이벤트를 통해 ‘준비됨’을 알 수는 있지만, 완료를 직접 관리하는 쪽은 애플리케이션이다).
Asynchronous + Non-Blocking
이 조합은 요즘 흔히 말하는 “진짜 효율 좋은 비동기”에 가깝다.
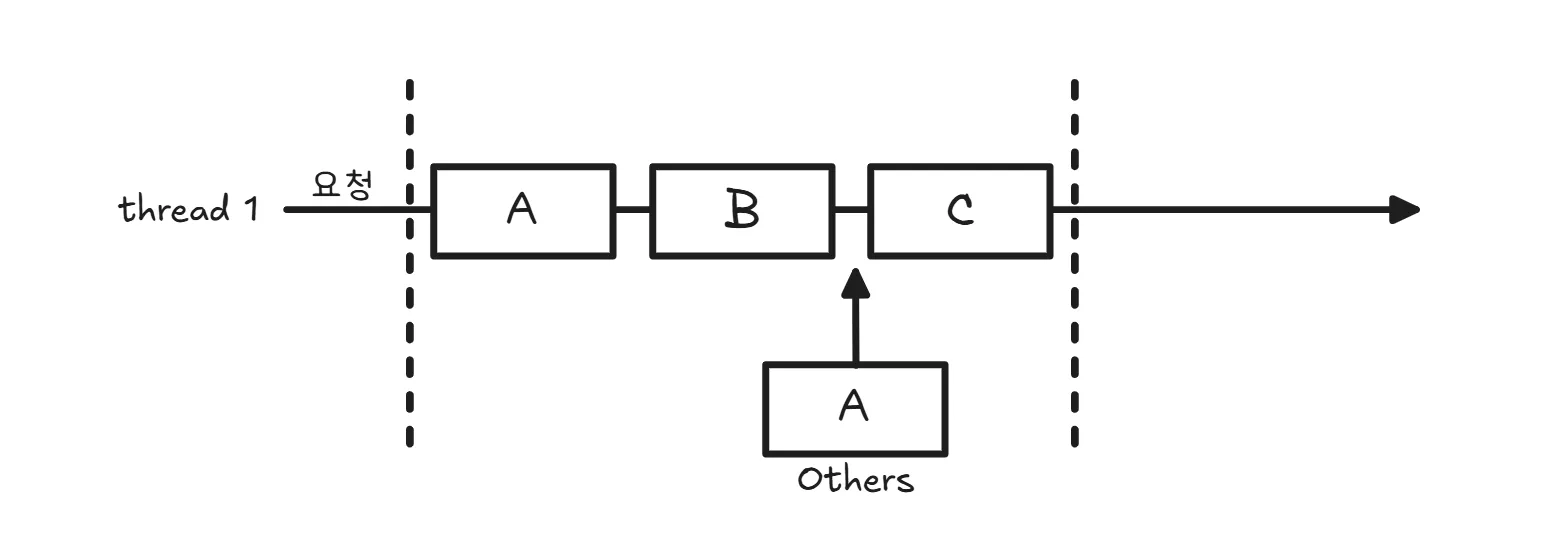
호출한 스레드는 결과를 기다리지 않고, 작업을 수행하는 스레드조차 I/O 때문에 멈추지 않는다. I/O는 OS나 런타임이 맡아서 처리하고, 완료되면 이벤트로 알려주거나 콜백을 실행해준다. 그래서 스레드는 대기(블로킹) 없이 계속 다른 요청이나 다른 작업을 처리할 수 있다.
이 방식은 적은 수의 스레드로도 높은 처리량을 만들 수 있지만, 대신 코드 흐름이 직선적이지 않고 이벤트 기반으로 흘러가기 때문에 구조가 복잡해질 수 있다. Netty나 Spring WebFlux가 이런 모델 위에서 동작한다.
Asynchronous + Blocking
이 조합이 사람들이 가장 헷갈리는 부분이다. 비동기인데 블로킹이라니, “비동기면 기다리면 안 되는 거 아닌가?” 같은 생각이 들기 때문이다. 그런데 여기서 핵심은 비동기의 의미가 “아무도 기다리지 않는다”가 아니라, “호출한 흐름이 기다리지 않는다”는 점이다.

비동기에서는 호출한 스레드가 결과를 기다리지 않고 바로 다음 일을 한다. 대신 실제 작업은 다른 곳으로 넘겨지고, 그 다른 곳(대부분 다른 스레드)에서 블로킹이 발생할 수 있다. 즉 기다림이 사라진 게 아니라, 기다림의 주체가 호출자에서 분리된 것이다. Spring의 @Async가 대표적인 예인데, 요청 스레드는 메서드를 호출하고 바로 반환받은 뒤 다음 흐름을 계속 타고, 내부 작업 스레드는 JDBC 같은 블로킹 I/O를 수행하며 결과를 기다린다. 그래서 “비동기 + 블로킹”은 호출자의 흐름은 비동기지만, 시스템 어딘가에서는 스레드가 블로킹으로 기다리고 있는 구조다.
현실적인 구현에서는 비동기처럼 보이지만 내부적으로는 다른 스레드에서 블로킹 I/O를 수행하는 경우도 많다. Spring의 @Async나 ExecutorService가 대표적인 예다. 호출한 쪽에서는 비동기처럼 동작하지만, 내부적으로는 스레드를 더 사용해서 블로킹 작업을 처리하고 있다.
백엔드 아키텍처 관점에서의 동기와 비동기
현대 백엔드 시스템은 여러 개의 마이크로서비스로 구성되는 경우가 많고, 이들 사이에는 빈번한 통신이 발생한다. 동기 통신에서는 A가 B를 호출하고, B가 다시 C를 호출한 뒤 모든 응답이 돌아와야 A의 처리가 끝난다.

이 구조에서는 중간에 있는 서비스에 문제가 생기면 장애가 그대로 전파된다. C에 문제가 생기면 B가 영향을 받고, 결국 A까지 영향을 받게 된다. 또한 호출이 연쇄적으로 이어지면서 지연 시간이 누적된다.
비동기 통신에서는 메시지 큐를 사용하는 구조가 자주 등장한다. A는 메시지를 큐에 넣고 바로 자신의 처리를 끝낸다. B는 큐를 계속 보고 있다가 메시지가 들어오면 처리하고, 그 결과를 다시 큐에 넣는다. C도 같은 방식으로 동작한다.

이 구조에서는 특정 서비스에 문제가 생기더라도 장애가 전체 서비스로 즉시 전파되지 않는다. 메시지 큐가 중간에서 완충 역할을 해주기 때문이다. B나 C에 문제가 생겨도 메시지는 큐에 남아 있고, 서비스가 복구된 이후 다시 처리할 수 있다. 서비스 간 결합도가 낮아지고, 시스템 전체의 안정성이 높아진다.
메시지 큐를 구현하는 대표적인 기술로는 RabbitMQ와 Kafka가 있다. RabbitMQ는 전통적인 메시지 브로커로, 비교적 단순한 이벤트 전달과 작업 큐에 적합하다. Kafka는 대용량 이벤트 스트리밍을 전제로 설계되어, 높은 처리량과 메시지 저장, 재처리에 강점을 가진다. 둘 다 “비동기 통신”이라는 큰 개념 안에 있지만, 사용 목적과 특성은 조금씩 다르다.
메시지 큐는 언제 사용하는 게 좋을까..?
막상 정리해보니, 비동기 통신이나 메시지 큐가 만능처럼 느껴지지는 않았다. 장애 전파를 줄이고, 서비스 간 결합도를 낮춰준다는 장점은 분명하지만, 그렇다고 항상 이 방식이 더 좋은 선택은 아닌 것 같다.
예를 들어 즉각적인 응답이 필요하고, 요청과 응답의 관계가 명확하며, 실패를 바로 사용자에게 알려야 하는 경우에는 여전히 동기 API가 더 자연스럽다. 로그인이나 결제 승인 같은 기능은 처리가 끝났는지 아닌지가 바로 중요하고, “나중에 처리되었다”는 방식이 오히려 문제를 만들 수 있다.
반대로 한 방향으로 흐르는 처리라면 이야기가 달라진다. 실패하더라도 재시도가 가능하고, 처리 시간이 길거나 부하가 큰 작업이라면 메시지 큐를 사용하는 쪽이 훨씬 안정적이다. 알림 발송이나 로그 수집, 이벤트 전파 같은 작업은 굳이 요청을 보낸 쪽이 결과를 끝까지 기다릴 필요가 없다.
결국 내가 내린 기준은 단순하다.
이 요청이 지금 당장 응답을 받아야 하는지, 그리고 처리가 한쪽 방향으로 흘러도 괜찮은지다. 이 두 가지에 따라 동기 통신을 쓸지, 비동기 통신과 메시지 큐를 쓸지가 자연스럽게 나뉜다.
이번 글에서는 동기와 비동기, 블로킹과 논블로킹을 기다림의 유무가 아니라 제어 책임과 흐름의 관점에서 정리해봤다. 스레드 수준에서의 차이를 그림으로 정리하고, 이를 서비스 간 통신으로 확장해 동기 API 체인과 메시지 큐 기반 비동기 통신이 어떤 차이를 가지는지도 함께 살펴봤다.
정리해보면 중요한 기준은 단순하다. 지금 이 요청이 즉각적인 응답을 필요로 하는지, 그리고 처리가 한쪽 방향으로 흘러도 괜찮은지다. 이 기준에 따라 동기 통신과 비동기 통신, 메시지 큐 사용 여부가 자연스럽게 갈린다.
다음 글에서는 이 개념들이 실제 코드에서는 어떻게 보이는지를 다뤄볼 예정이다. Spring MVC와 WebFlux의 처리 모델을 비교하고, 이어서 Kafka나 RabbitMQ 같은 메시지 큐가 어떤 상황에서 쓰이고, 둘은 어떤 차이를 가지는지도 정리해보고 싶다.
쉬운코드: 비동기 프로그래밍, 비동기 I/O, 비동기 커뮤니케이션.. 각 맥락에 따라 비동기(asynchronous)의 의미를 설명합니다!
https://youtu.be/EJNBLD3X2yg?si=Ez6YhKNtvwi1XPEy
'CS > OS' 카테고리의 다른 글
| I/O Multiplexing: Reactor 와 Proactor (IOCP) (0) | 2026.01.21 |
|---|---|
| I/O Multiplexing: Select, Poll, 그리고 Epoll (0) | 2026.01.19 |
| Block I/O vs Non-Block I/O 무슨 차이지..? (0) | 2026.01.19 |